

In past blogs I have expressed my love for the GREP functions in InDesign. GREP is not only functional, but for me it’s a lot of fun.
I enjoy working with strings of text, manipulating things en masse to cause changes that would otherwise take too long.
An example I have written about in the past is that of reversing names in a list from last name-first to first name-first. I have written a handful of GREP search instructions to do this, and none of them is completely perfect. That is still the case, but I discovered a couple of new GREP commands in InDesign that are very useful, and I want to share my success with you.
The pattern of text that I work with is my class lists, which are sent to me by the university at the beginning of each quarter. These come with an overload of information, and I have to filter-out only the names to make a roll sheet for the first day of class.
The patterns look like this:
7 Bauer, Marcus Desmond mbauer09 GRC Freshman 3 Enrolled No
The numeral is the number of the student in the list, then last name, first name, middle name (or not), e-mail address, the student’s major, class level, the number after that is the units of the class, and then their enrollment status (always “Enrolled”) and whether the student has flagged his or her information to be kept private. When I look at the text, I look for patterns that I can search for:

I only need the second and third elements of all of this data, so GREP can help me accomplish this in two ways: 1, It strips off the unnecessary data, and 2, it reverses the last name and the first name.
The implementation of GREP in InDesign is pretty good, but it varies slightly from the more “pure” GREP that is found in UNIX and in some text editing environments. But, that’s OK with me, because InDesign is where I work most often with text, and it’s very helpful to be able to use it there.
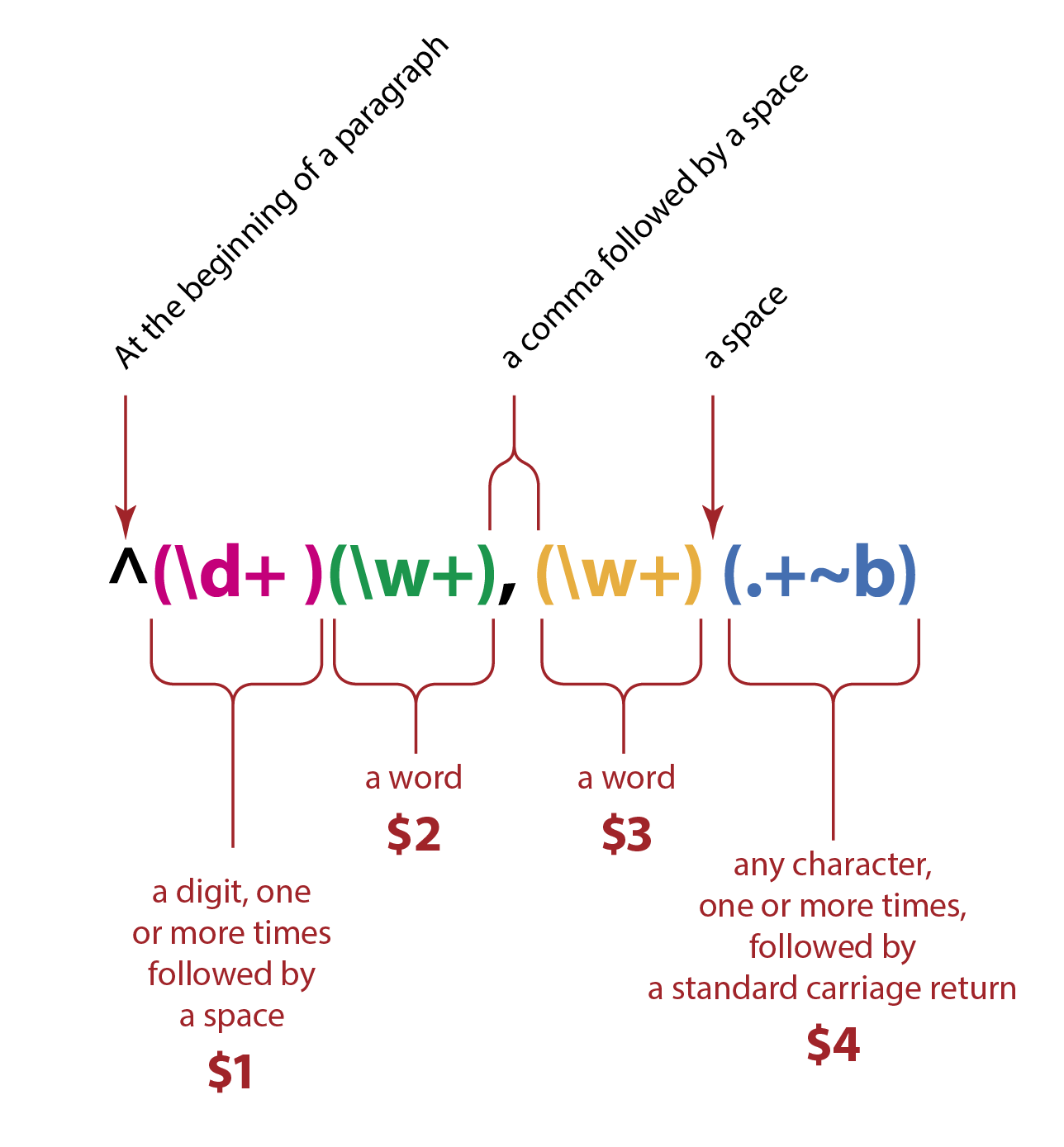
This is the anatomy of my GREP search string in InDesign. It uses the commands that are new to me: the at-the-beginning-of-the-paragraph, and “find a word.”
The “new” functions that I have discovered are the “at the beginning of a paragraph” command, which is a simple caret at the beginning of the command string, and the “find a word” command, which I use twice in this search.
\w+ is the command to find a word. Words are defined as characters in any order, in any case, not separated by non-alphabetical characters (which you will see in my example here). Word does find number strings* and the underscore, but no other characters.
So, to find the second and third data elements (both words), I search for (\w+) twice, and I get both words.
They’re separated by a comma and a space in the text, so I put those characters in between, and that works also.
To capture the numbers at the beginning of the paragraph (and no others), I use the command ^(\d+ ) which finds any digit, one or more times, followed by a space. I put this inside of parentheses to pass it to a memory space called $1. Later I will not use that memory space, but I need to capture it for the short term.
I then search for “a word” and pass those words to memory positions $2 and $3 for the last and first names, respectfully.
After the student’s names there is all that other information that I don’t want. I use GREP’s command for finding any character (this includes letters, numbers, figures – anything) followed by a standard carriage return. This gets rid of everything after the student’s first name.
Once I have all that, I put the first and last name back in the opposite order, and I’m done.
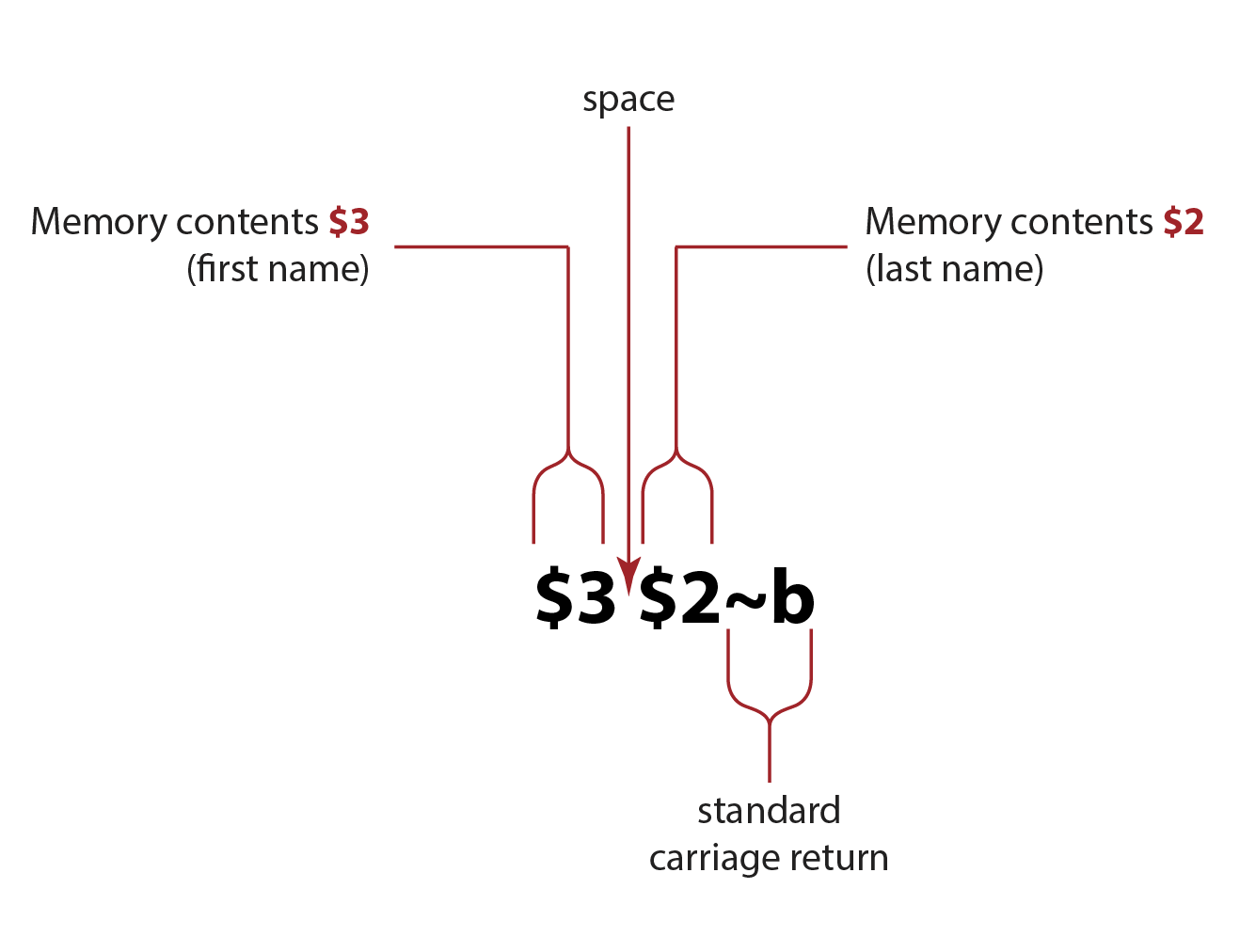
This is the replace string for the search above. It’s very simple: put the content of Memory 3 followed by the content of Memory 2 back on the line, separated by a space, and followed by a standard carriage return. The comma after the last name is automatically dropped because it was not inside the parentheses in the search string.
In my earlier method for this, my search criteria usually failed when a capital letter showed up in a name, like DuPont. This new method works for those kind of names. But, it doesn’t work for names that have spaces in them, nor for words with hyphens.
In the past I had to fix those names by hand, and I still have to do that, but with fewer names now.

This is the list as I receive it from the university.

…and this is the same list with potential problems highlighted in red. In my previous GREPping dramas, I have had to fix all of the lines marked in red.
By using the new search criteria, I can fix most of these, but not all:

Notice that only two of the four potential problems were not processed correctly: those with spaces in the last name, and one with a hyphenated last name.
It’s easy to fix those that are not processed by the search string, and it only takes a few seconds.
* An addendum (November 9, 2014): Though it doesn’t make any difference in performance, it is possible to search for three “words” – the first being the serial number, the second being the student’s last name, and the third being his or her first name. The search string looks like this:
^(\w+) (\w+), (\w+) (.+~b)
The result is identical.