

Over the years we have needed to convert scanned images of text into editable text. Companies have invested heavily in the process of extracting text from printed documents, some have lost fortunes in this effort. Some have solved problems, while some have created greater problems. The need to convert images into editable text seems to have waned in recent years, yet simultaneously, the ability to do it has gotten easier, courtesy of the Secret Projects Division of Adobe Systems, Incorporated (I made that up).
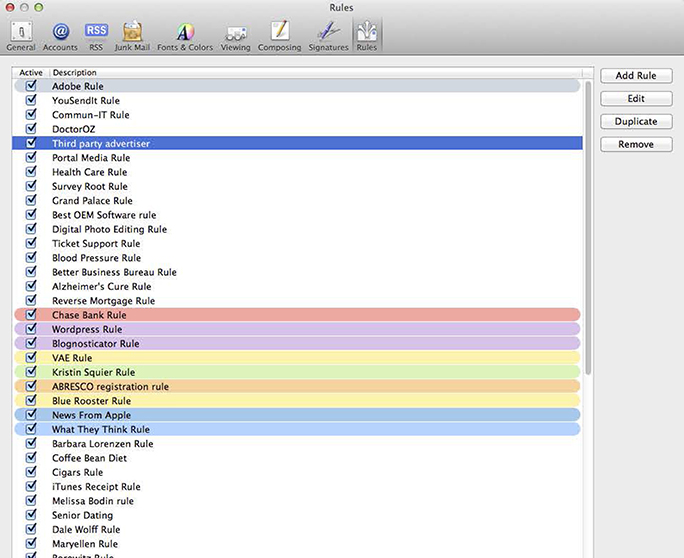
This is a screen capture of the Rules menu in Apple Mail. I wanted to convert the text in it to an editable file for this blog. I couldn’t select the text, so I used Acrobat Professional to convert the screen capture into editable text.
The ability of Adobe Acrobat Professional to convert a scanned document into text is uncanny. I have used it twice in the last week to make text from scans, and I found it to be a life-saving tool. There are two approaches: One assumes you just want the text without the original scan, the second assumes you want the original PDF with searchable text within. Here is technique number one: Scan the document, then save it from Photoshop as a Photoshop PDF. This puts the scan into a PDF container. Open the resulting file in Acrobat Professional.
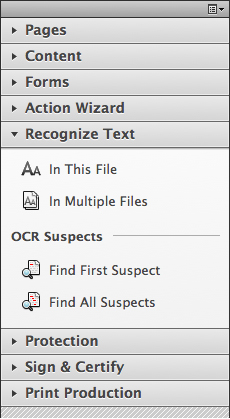
This is the Tools menu for Recognizing Text in Acrobat Professional. I chose the In This File option to extract text from the PDF document I had open at the time.
In Acrobat, choose Tools, then choose Recognize Text, and then In This File. A minute later (depending on the size of the document), without any visible change in the document, any text found will be created, and it under- (or over) lies the visible text in the document. Once created, the text is searchable, and the document can be saved with the text in it. I use this technique to create text, then I copy the text out of the PDF, and paste it into a word processor to do something else with it.
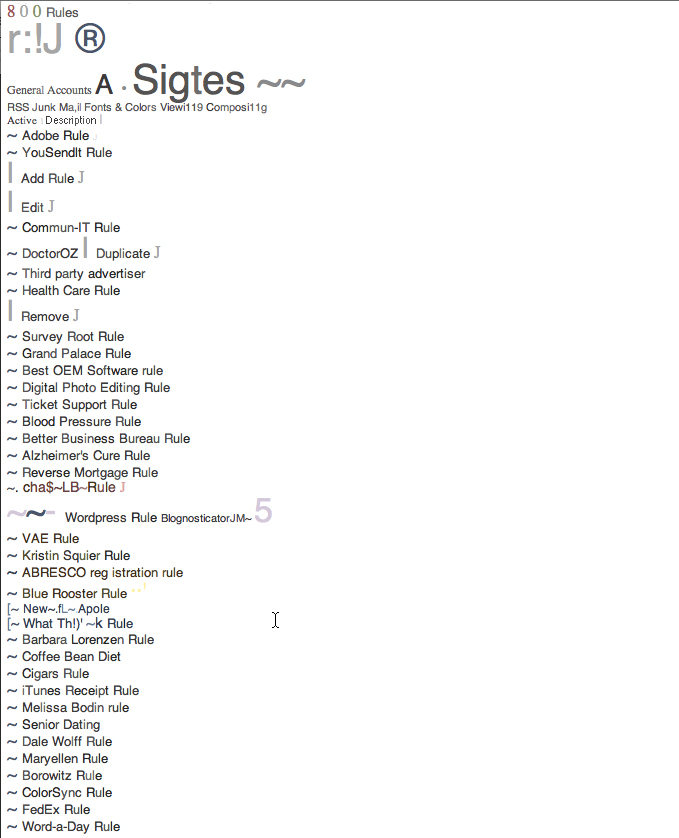
This is the text I was able to extract from the image file above. Notice that it intermixes the copy on the left and top of the screen with the copy on the right. It even recognized the text in the icons in the title bar. Some of it is nonsense, but it’s easy to identify and delete. In the end, I had about ten lines out of 124 with errors. The most common cause of errors was the highlighted lines in color (see “Chase Bank Rule”), where Acrobat had difficulty separating the text from the background color, and made quite a few errors.
For the second approach, Save the document after Recognizing Text, and you have an update of the original PDF with searchable text within. The only problem with this technique is that all the text in the scanned document is turned into searchable text, including text in buttons like “OK” and “Edit.”
If you are copying the text out of the PDF and pasting it into a word processor, you will have to excise those erroneous entries, a process that is quite easy because they are easy to identify. And, because no method yet devised can read 100 percent of scanned text correctly, it’s always a good idea to run a spell-check on the resulting text to find errors.
My tests of this process also reveal that the contrast of scanned text also matters. In the example shown here, some of my rules are highlighted in yellow, blue and other colors. It was in those lines where the greatest number of errors occurred. One solution would be to remove the color highlighting, or to edit the document in Photoshop to remove the color, then make a PDF, and Recognize Text.